



2025 has been a defining year for AI. OpenAI’s GPT-5 and Anthropic’s Claude Sonnet 4.5 have raised the bar once again, each one aiming to blend stronger reasoning, longer memory, and more autonomy into one seamless system. Both are built to handle coding, research, writing, and enterprise-scale tasks, yet their design philosophies differ sharply.
This breakdown explores how the two stack up across performance, reasoning, coding, math, efficiency, and cost, helping users and teams decide where each model truly shines.
A Quick Overview
Claude Sonnet 4.5 builds on Anthropic’s refined Claude family. It extends memory across sessions, handles million-token contexts via Amazon Bedrock and Vertex AI, and features smart context management that prevents sudden cut-offs. It can run autonomously for 30 hours on extended tasks, making it ideal for ongoing workflows.
Meanwhile, GPT-5 is OpenAI’s flagship successor to GPT-4, tuned for agentic reasoning, where the model plans, executes, and coordinates tools on its own. Its adaptive reasoning system dynamically chooses between shallow or deep “thinking” paths, letting users balance speed, cost, and depth per task. GPT-5 also offers specialized variants (Mini, Nano) for lighter workloads.
Reasoning and Analysis
Both models far exceed their 2024 counterparts, but they differ in how they reason.
GPT-5’s deep-reasoning mode significantly boosts performance in multi-step logic, scientific, and spatial tasks. It can break problems into chains, test sub-hypotheses, and self-correct mid-process. However, disabling this mode reduces accuracy sharply, it can be brilliant when “thinking deeply,” but more variable when not.
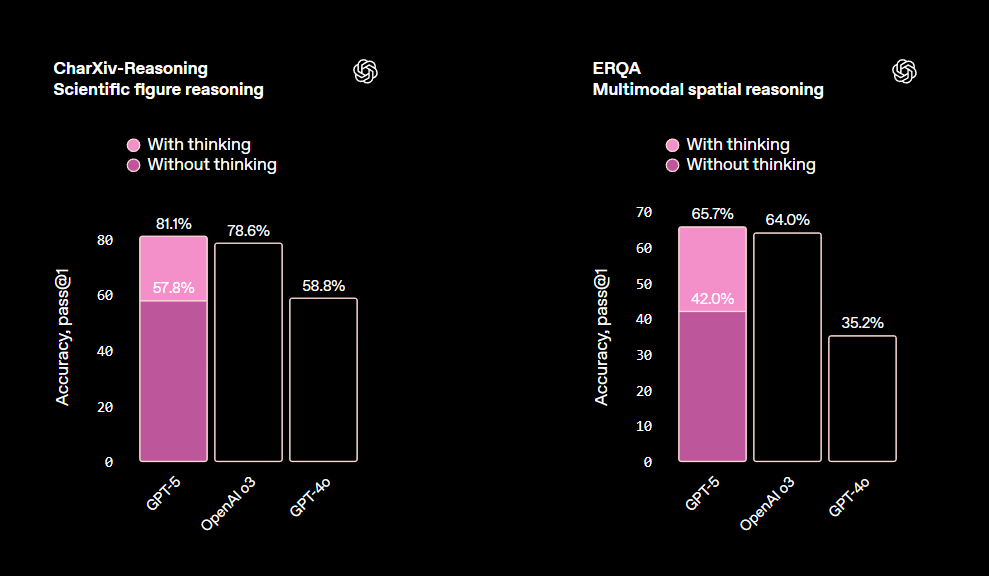
Claude Sonnet 4.5, by contrast, stays stable even without added configuration. It’s particularly strong in financial, policy, and business logic, where structure and coherence matter more than creative leaps. For enterprise Q&A or decision support, that predictability is valuable.

If you want an AI that reasons steadily, Claude takes the lead. If you need exploratory logic (i.e. complex hypothesis testing or cross-domain synthesis) GPT-5’s deeper path is unmatched.
Math and Structured Problem Solving
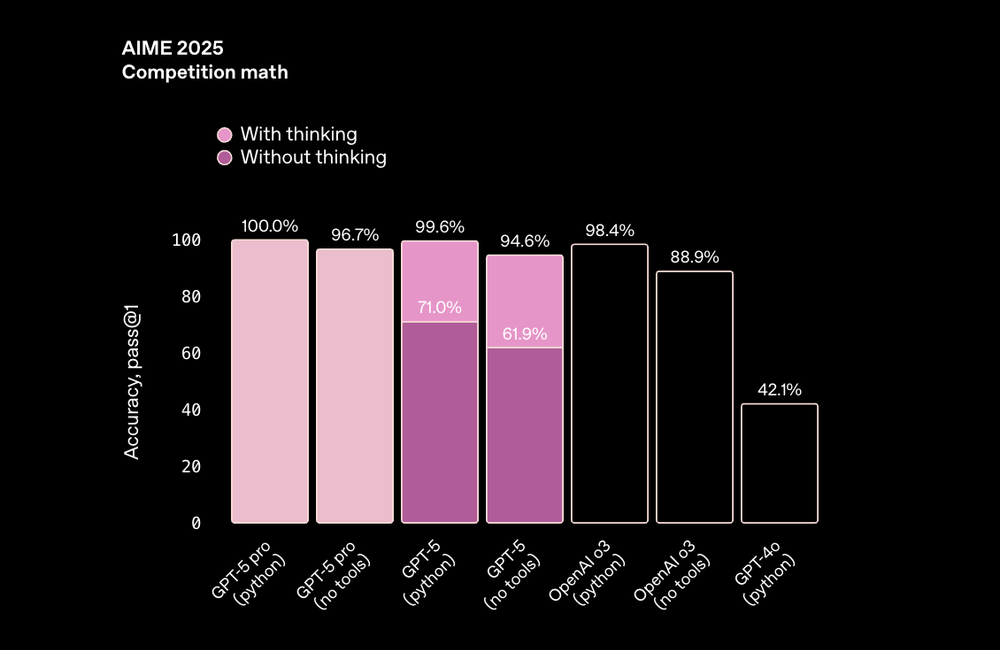
As seen in the benchmarks provided by Anthropic, Claude Sonnet 4.5 continues its consistency streak. Whether calculating directly or using Python tools, it achieves top-tier math accuracy. This means it handles structured logic even in constrained environments.
GPT-5 also reaches near-perfect accuracy, but only when tool use and reasoning depth are active. Disable them, and results drop noticeably. It relies heavily on its reasoning pipeline to stay sharp.
Verdict:
- Claude Sonnet 4.5: dependable out-of-the-box math solver.
- GPT-5: flexible but needs tuning to perform at its best.
Coding and Software Engineering
When it comes to coding, the two models diverge in style.
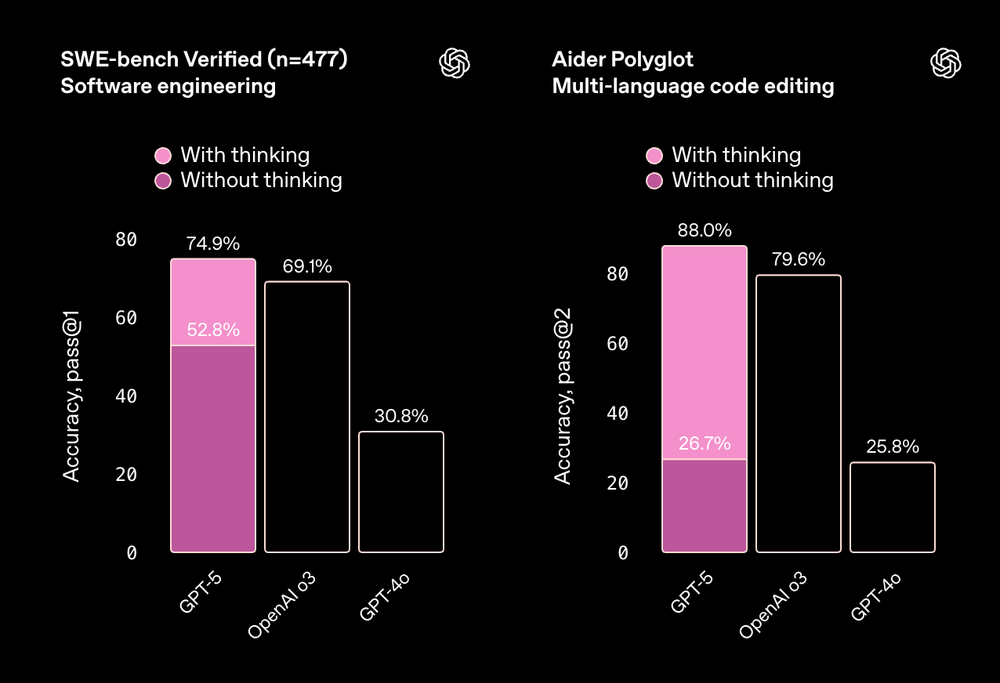
Claude Sonnet 4.5 delivers stable performance without special tuning. In tests resembling HumanEval+ and MBPP+, it maintains high accuracy across conditions, making it dependable for production pipelines. Its strength lies in consistency, results rarely fluctuate, which is crucial for enterprise use.

By contrast, GPT-5 achieves higher peak scores when its advanced reasoning is enabled, especially in multi-language or large-project contexts. In JavaScript and Python refactoring tasks, for instance, it outperformed Sonnet when its “high-reasoning” mode was active — though baseline runs without that mode varied more.
For agentic coding, where the AI calls external tools or terminals, Sonnet 4.5 often executes with fewer dropped commands. GPT-5, on the other hand, can chain more tool calls simultaneously, making it better for complex orchestration, provided you configure it carefully.
Verdict:
- Claude Sonnet 4.5: predictable, steady engineering partner.
- GPT-5: versatile powerhouse, but performance hinges on setup.
Cost and Efficiency
GPT-5 is clearly cheaper per token, particularly for large inputs. Its adaptive router also saves compute by running simple prompts on lighter paths.
Claude Sonnet 4.5 charges more but maintains predictable latency, a key factor for production environments that value reliability over marginal savings. For very large prompts, its cost rises faster than GPT-5’s, though batch discounts narrow the gap.

TL;DR: GPT-5 wins on price and scalability, whereas Claude wins on timing consistency and stability.
Pricing for Premium Plans
Beyond API access, both OpenAI and Anthropic offer premium subscriptions for individual users, which differ in features and pricing.
ChatGPT Plus, powered by GPT-5, is priced at $20 per month, giving users priority access to GPT-5, faster response times, and early access to new features and memory. OpenAI’s unified ChatGPT experience also includes file uploads, image generation, and custom GPTs.
Claude Pro, meanwhile, costs $20 per month as well and grants access to Claude Sonnet 4.5, offering faster responses, higher rate limits, and longer context windows. While it lacks built-in multimodal tools, Claude focuses on text clarity and structured reasoning, appealing to researchers, analysts, and writers seeking dependability over versatility.
TL;DR: both Plus plans are tied in price; what sets them apart, however, is their offering.
Different Strengths for Different Needs
It’s tempting to crown one “best,” but GPT-5 and Claude Sonnet 4.5 serve different priorities for different users and teams.
- Claude Sonnet 4.5: best for reliability and sustained performance. If you want consistent outputs and clear memory behavior, Claude delivers.
- GPT-5: best for depth, flexibility, and scalability. When configured properly, it surpasses rivals in creative reasoning, multimodal integration, and adaptive tool use.
Most teams may find the strongest setup is multi-model, using Claude where consistency matters most, and GPT-5 for data-intensive workflows.
Ultimately, these aren’t just chatbots anymore, they’re full-fledged digital collaborators, each with distinct personalities. Claude Sonnet 4.5 is your calm, methodical analyst. GPT-5 is your ambitious polymath. Which one you pick depends less on their individual benchmarks and more on your mission.
This article is for general information purposes only and is not intended to constitute legal, financial or other professional advice or a recommendation of any kind whatsoever and should not be relied upon or treated as a substitute for specific advice relevant to particular circumstances. We make no warranties, representations or undertakings about any of the content of this article (including, without limitation, as to the quality, accuracy, completeness or fitness for any particular purpose of such content), or any content of any other material referred to or accessed by hyperlinks through this article. We make no representations, warranties or guarantees, whether express or implied, that the content on our site is accurate, complete or up-to-date.
